Content from Introduction
Last updated on 2024-03-12 | Edit this page
Computational thinking is an essential prerequisite for anyone wanting to learn to program computers and write code.
Different definitions of computational thinking exist. However, computational thinking can be described as a set of strategies to enable people to solve problems, especially complex ones. The BBC provides a good definition:
“Computers can be used to help us solve problems. However, before a problem can be tackled, the problem itself and the ways in which it could be solved need to be understood. Computational thinking … allows us to take a complex problem, understand what the problem is and develop possible solutions. We can then present these solutions in a way that a computer, a human, or both, can understand.”

Problem scenario
Four friends are out on an afternoon walk through a forest. Their plan was to go only for a short hike, so no-one has brought along an emergency beacon, and all mobile phones were left in the car. Everyone has a water bottle, though these are no longer full, but no-one brought a map as the trail they were planning to follow is clearly marked and signposted.
However, they all left the trail together in a great rush when they heard a distant cry for help. After some fast walking through dense woods trying and failing to reach whoever made that distress call, they realise quite suddenly that they are lost. The cries sound much more distant now, but when they retrace their steps to what they thought was the path to strike out in a different direction, they cannot find it.
The sun is starting to sink, it is growing colder, they are now hopelessly lost, and everyone is starting to feel hungry …
So what do they do?
Breaking down a complex problem
This is a complex problem. As we progress through this lesson, we will learn how to break this problem down so that we can start to solve it. Let’s first come to grips with what computational thinking is.
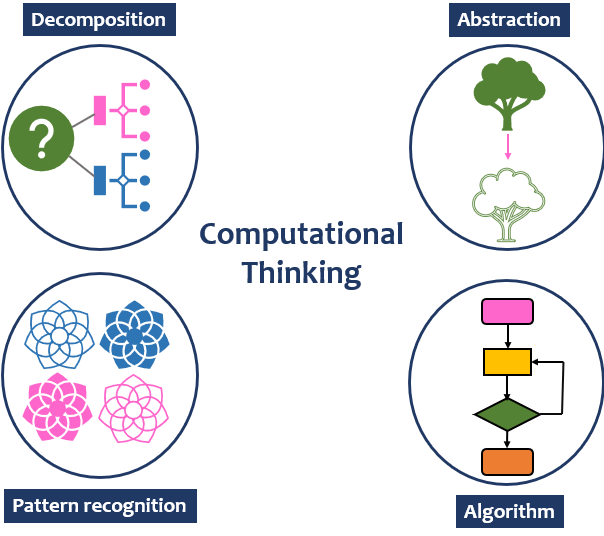
There are four essential components of computational thinking:
- Decomposition – breaking a problem down into more manageable parts so that solutions can be found for each. This is also called factoring.
- Pattern recognition – looking for similarities within a problem or with other problems so that past solutions or knowledge can be re-used
- Algorithms – developing step-by-step solutions to each part of the problem
- Abstraction – generalising (abstracting) the important detail to make a solution reusable
Professor Jeannette Wing raised computational thinking as an important issue for researchers in a 2006 paper. She stated, “Informally, computational thinking describes the mental activity in formulating a problem to admit a computational solution. The solution can be carried out by a human or machine, or more generally, by combinations of humans and machines.”

Wing believes that computational thinking is just as important a skill for school children to learn as reading, writing and arithmetic. Increasingly, schools are including computational thinking in school curricula.
But first, do no harm …
While automation brings many benefits, such as lightning-fast data capture and analysis, it can also render decisions and analysis opaque and overly rigid. The famous phrase ‘Computer says no’ from the TV show Little Britain is a perfect example of this kind of intransigence. Experiences of this kind will frustrate users.
Algorithms have also been criticised for bias. As Karan Praharaj says: “Algorithms do what they’re taught. Unfortunately, some are inadvertently taught prejudices and unethical biases by societal patterns hidden in the data … When these algorithms do the job of amplifying racial, social and gender inequality, instead of alleviating it; it becomes necessary to take stock of the ethical ramifications and potential malevolence of the technology.”
Use automation, but use it wisely, and ethically, and always with lashings of human oversight.
What’s next?
Our friends in the forest are still in the shouting, blaming and squabbling stage of their predicament, so while they are occupied in NOT solving their problem, we will look at computational thinking in a little more detail and examine how we can use each step to solve a maths problem.
References
British Broadcasting Corporation BBC Bitesize. KS3: Introduction to computational thinking.
- Wing, Jeannette M. “Computational Thinking”, Communications of the ACM, March 2006, Vol. 49 No. 3, Pages 33-35. DOI: 10.1145/1118178.1118215.
Content from Exercise
Last updated on 2024-03-12 | Edit this page
In this exercise, we will see how computational thinking can be used
to add up all the numbers between 1 and 200 in our heads,
i.e. 1 + 2 + 3 + 4 and so on. We should be able to do this
in less than a minute.
Seems impossible?
It’s not.
Using the first computational thinking step - Decomposition - we break the problem up into smaller pieces. Rather than trying to add the numbers up sequentially, which would be challenging for many people to do in their heads, let’s approach the task in a different way.
The answer is 201.
The answer is 201.
The answer is 201.
Pattern recognition
Using our second step - Pattern recognition - we should be
able to spot a clear pattern, i.e. that each pair of numbers appears to
add up to 201.
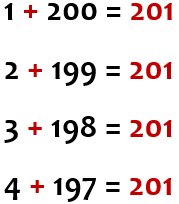
If we follow this same process with all the numbers
between 1 and 200, we will end up with 100 pairs, each
of which will add up to 201.
Algorithm
Using an Algorithm - another name for a series of steps - how do we calculate the final total?
We multiply the number of pairs (100) by
201 (the total to which each pair adds up).
100 * 201 gives us the answer of
20,100.
So far, so good.
Now, what about about our fourth step, Abstraction?
Abstraction
Abstraction will enable us to generalise from that experience, i.e. repeat the process we used to add up all the numbers between 1 and 200 to add up a different set of numbers, e.g., 1-500.
The Algorithm will be
(number to be added divided by 2) multiplied by
(number to be added +1). We can express that as an
algebraic formula:
(x/2) * (x + 1)
where x is the
number to be added.
That’s it! Using those four key steps, we have learned the basics of computational thinking.
Content from Computational thinking in practice
Last updated on 2024-03-12 | Edit this page
While thinking computationally is a prerequisite for programming, programming and computational thinking are not the same thing.
| Programming | Computational thinking | |
|---|---|---|
| instructs a computer to carry out a sequence of steps in a particular order. | is the process that helps decide what those steps will be, i.e. what the computer will be told to do. |
Computers are precise, and computing instructions must be clear and unambiguous, as the computer cannot think - it can only follow orders. Unlike humans, computers do not get bored or distracted, they process data very quickly, and will carry out the same tedious, repetitive tasks over and over again without making mistakes.
Computational thinking in our daily lives
Subconsciously, we practise computational thinking every day of our lives. As Jeannette Wing stated:
“Computational thinking describes the mental activity in formulating a problem to admit a computational solution. The solution can be carried out by a human or machine.”
Every time we need to plan to do something, we use some of the steps of computational thinking such as problem breakdown, pattern recognition and developing algorithms.
Project managers use computational thinking to plan complex activities such as building a tunnel or revamping a playground.
Epidemiologists use it to identify patterns that help predict how a disease outbreak will spread.
Parents use it to juggle work, parenting, community responsibilities and housework.
Lost hikers can use it to try to find their way out of the forest.
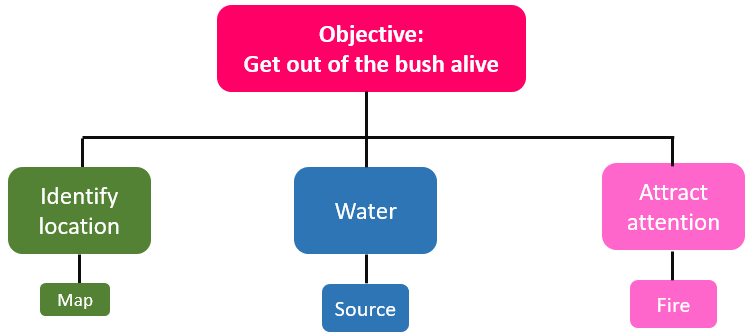
Breaking problems down with structure diagrams
When trying to solve problems, it is essential to break them down into their constituent parts. Pasting sticky notes on a wall is one way to visualise the necessary steps.
Structure diagrams also allow you to plan problem breakdown visually. At the top should be the objective, and the steps underneath should start with high level considerations. These high level considerations can then be broken down into smaller and smaller steps.
In the hiking scenario, the group of four people have to try to solve the problem of being lost. This diagram is the very start of their thinking about their immediate needs.
Content from Computational thinking in programming
Last updated on 2024-03-12 | Edit this page
Decomposition is crucial in any kind of problem breakdown, but especially so in programming. The computer must be told precisely what to do, and in what order, so problems must be broken down into discrete parts and each section coded appropriately.
Suppose we want to find the ten words most commonly used in a text. How might we go about that?
Linear code
While there are many different ways to do this task, this is one way, where all the commands are run in a linear sequence, e.g.,
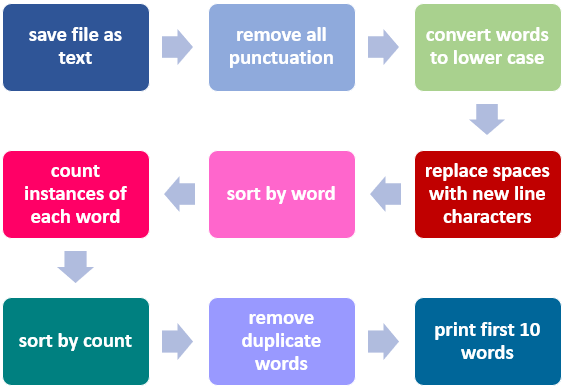
First we save the file in .txt format to eliminate all
the “smart” formatting created by programs like Word (as they would
otherwise introduce a messy bunch of extraneous characters). Then we
progressively eliminate everything from the text that is not a word,
i.e. punctuation.
Converting all the words to lower case means we end up with a single
version of each word - not two. This is important because, to a
computer, Word (starting with an upper case letter) does
not equal word (starting with a lower case letter) - it
treats them as two separate entities.
By replacing spaces with new line characters, each word
will end up on its own line, which makes them easy to sort
alphabetically and then count.
Each part of the sequence would need to be individually programmed. Fortunately, programmers can adapt code that others have already used to do similar tasks, such as code to identify letter, number or word frequency. Once you are coding, this is where the computational thinking skill of pattern recognition comes in - identifying similar code that can be used for or adapted to the specific problem you want to solve.
Content from Pseudocode
Last updated on 2024-03-12 | Edit this page
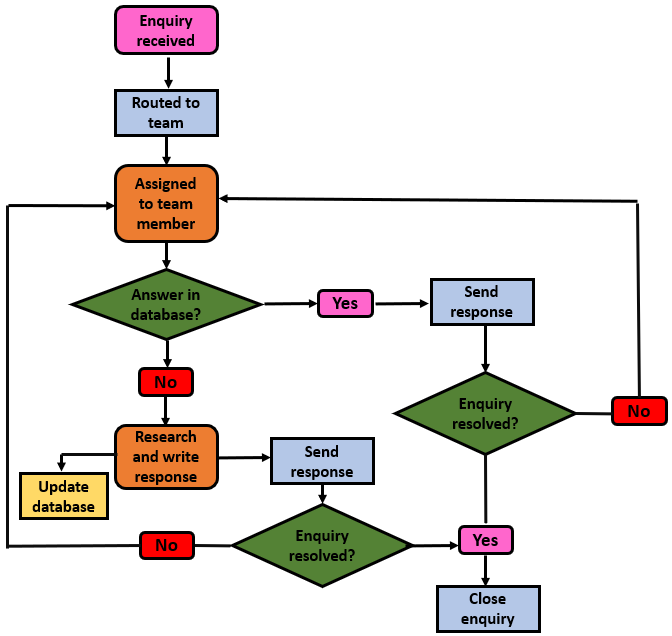
Regardless of programming language, pseudocode is a useful tool to break coding problems down. Pseudocode helps you list each step of a planned process so your steps are in a logical order before you code.
Pseudocode is also a good way to explain your needs to software developers or to run your ideas past people who may not be programmers.
Pseudocode example
Suppose we are fans of the Lord of the Rings novels, but we wonder how much the female character of Galadriel featured in the story compared to the male characters Frodo, Gandalf, Aragorn, Legolas and Boromir. We could flick through, say, The Fellowship of the Ring to check (which would be painfully slow), or we could run a short piece of code to count the number of times each character’s name is mentioned throughout the story. We could document those steps in pseudocode before writing any code to be sure we have covered all the things we will need to do.
Notes
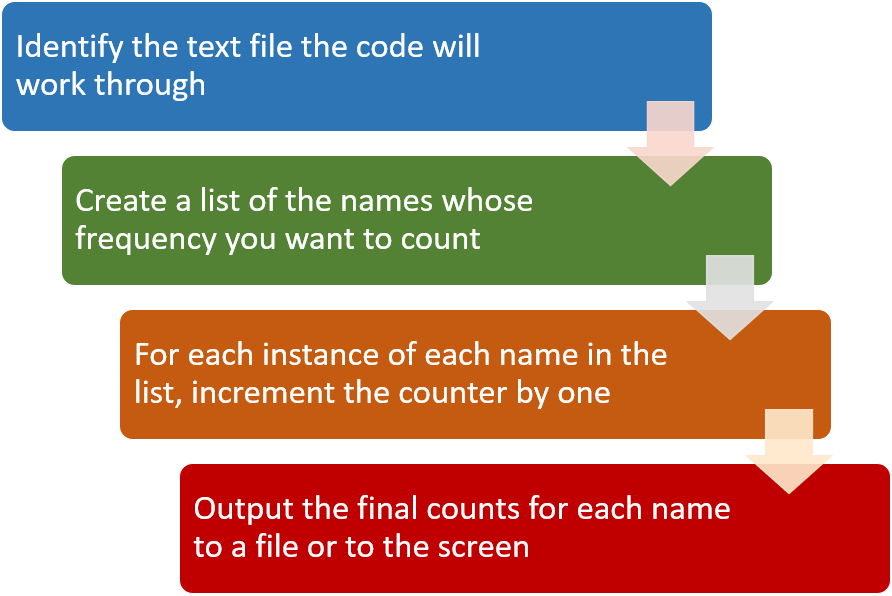
- The text
only version of The Fellowship of the Ring is the file the
code will process.
- The characters’ names, Galadriel, Frodo, Gandalf, Aragorn, Legolas and Boromir are the values the program will look for and count.
- A
.txtfile is important for this kind of activity, as all the “smart” formatting (i.e. curly quote marks, hyphens converted toemandendashes) that appear within a.docor.docxfile is stripped out when saving a.docor.docxfile as a.txtfile. - We could re-use the code to run a similar operation on The Two Towers and The Return Of The King, or we could adapt the code even further for any name or word frequency question we want to automate.
Spoiler alert - Galadriel gets only 35 mentions by name compared to Frodo’s 944.
Loops
The code that will be used to do this job is an example of a loop. Loops allow us to execute the same command over and over again until a certain pre-set condition has been met. In this case, the condition is to have counted all the appearances of each name on a designated list.
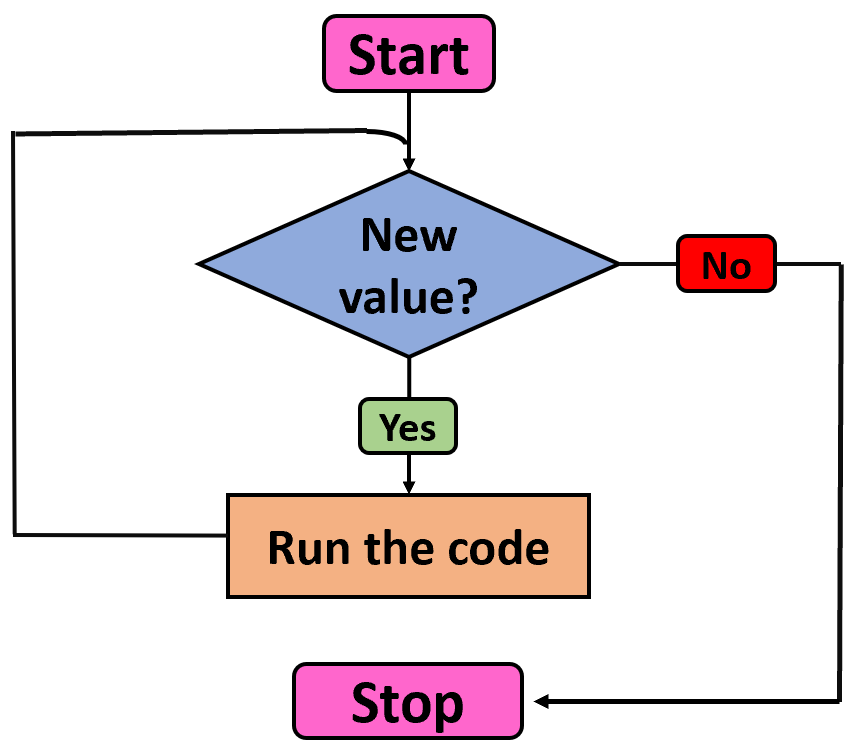
In the example above, the program will search all the way through the
text of The
Fellowship of the Ring, adding up all the appearances of the
first value in the list (Galadriel). Then it will go
through the text again to do the count for the second value
(Frodo). The same process will then be done for all the
other characters respectively, and then the program will report its
findings for each value. It will then stop running because the list of
names has been exhausted, i.e. the condition has been met.
The name values can also be called variables, because the
value will vary each time the loop runs through the text. Variables are
an important part of abstraction.
The same piece of code could be re-used for any word counting
exercise by changing the list variables and the input source. That would
be another example of abstraction.
Practice 1. Creating backup copies of files
In a folder, we have 250 image files for which we want to create backup copies before we process the images for archiving. Manually creating 250 copies of files seems like a very boring thing to do, so we are going to automate the workflow to create the backup copies.
Write some pseudocode of how you might automate this process.
Practice 2a. Tidying up
We have a large folder of files left over from a project that is now
finished. The files are all sitting in the one folder which makes it
hard to navigate. We want to archive the project and its files, but in
the process, we want to create folders by file type, e.g.,
.pdf, .jpg, .doc, so that anyone
wanting to access those particular file types can do so easily. We also
want to delete files that have no file extensions. New folders will need
to be created and the different files moved into them by file type.
Write some pseudocode of how you might automate this process.
Practice 2b. Tidying up more carefully
In the process of doing the above, we actually made a few blunders. We accidentally deleted some files we should have kept either because they were mislabelled or they were missing a file extension. Because this automation is a complex operation that cannot be undone, we want to make sure we don’t make those kinds of mistakes again.
One way to do that is to check we have coded the workflow correctly before we finally execute the automation. Therefore we could introduce a step that mimics what would happen if we executed the script on the files, perhaps by printing the filenames we want to move or delete to the screen (or to a file) rather than actually deleting or moving them. That way we can check we are working on the correct files and only execute the final move workflow once we are sure we have everything right.
Write some pseudocode for that step of the process.
Practice 3. Managing incoming data
Suppose you have a number of acoustic listening devices set up in the forest. Every day, you receive an email from each device with an attached data file recording that day’s activity. In order to analyse the data from the devices, all the separate daily data files need to be combined weekly into a single file. It is important that each device ID is listed within a column in the combined data file to identify all the different locations.
In order to analyse the data over time, you need to append the weekly file digest to the existing, now very large, main data file. Before adding anything new, and in order to safeguard the integrity of the data, you need to create a backup of that main data file and send a copy of that backup file to your cloud storage account for safekeeping. Once the new data has been appended, you need to rename the new main data file with today’s date as part of the file name, and run software against the file to ensure the integrity of the data, e.g., to check that no data is missing (which might indicate a malfunctioning device).
Write some pseudocode of how you might automate this process.
Some potential solutions to these practice coding exercises can be found on the Solutions page.
Learning to program
This lesson should help you prepare to learn to code by understanding the process that coders use to break complex problems down into programmable parts.
Links to sites that teach coding and other resources on computational thinking are listed in the Resources section.
For later
Suppose you write that file movement script and it works a treat.
Why not get it to run every month to tidy up folders that invariably
become messy over time, e.g., your computer’s Downloads
folder?
Or, suppose you use a file naming convention that starts with
YYYY-MM-DD. Why not run a script annually to sort and
organize your documents by year?
Content from Potential solutions to practice exercises
Last updated on 2024-03-12 | Edit this page
Different people might approach these practice tasks in very different ways so these solutions are suggestions only. They are offered here to provide some guidance for people who might otherwise struggle with laying out steps.
Practice 1. Creating backup copies of files
In a folder, we have 250 image files for which we want to create backup copies before we process the images for archiving. Manually creating 250 copies of files seems like a very boring thing to do, so we are going to automate the workflow to create the backup copies.
This is a perfect task for a loop, as the task is simple and repetitive.
Steps in the copying process

Example code in the Unix shell
BASH
for filename in "*.jpg" "*.tif" "*.png"
do
cp $filename backup-$filename
echo $filename backup-$filename
done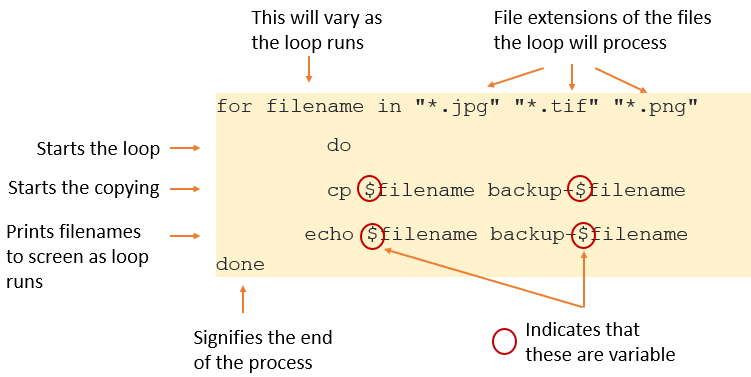
Notes
In the code example above, the loop will run through the folder
creating back up copies of all the files with the file extension
.jpg. As each file is copied, each original filename and
the filename of each new file will be printed to the screen.
Then the loop will restart and repeat the process for all the files
with the file extension .tif, again printing the original
filenames and the filenames of the new files to the screen.
Then the loop will restart and run through the folder a third time,
creating back up copies of all the files with the file extension
.png, again printing the original filenames and the
filenames of the new files to the screen.
The loop will then stop, as there are no more variables to work on.
Practice 2a. Tidying up
We have a large folder of files left over from a project that is now
finished. The files are all sitting in the one folder which makes it
hard to navigate. We want to archive the project and its files, but in
the process, we want to create folders by file type, e.g.,
.pdf, .jpg, .doc, so that anyone
wanting to access those particular file types can do so easily. We also
want to delete files that have no file extensions. New folders will need
to be created and the different files moved into them by file type.
Steps in the moving process
- Identify the different file types in the folder.
- Create new folders to house the different file types.
- Create a series of loops to work through the folder, file type by file type, moving the files to the correct folders.
- Once the final loop has run, delete all remaining files left within the main folder.
- Print filenames to the screen as the loop runs to verify it is working as required.
Using a shell script to automate the work
The task above could be fully automated using a shell script. A shell script is a text file containing a sequence of commands for a UNIX-based operating system that allows those commands to be run in one go, rather than by entering each command one at a time. Scripts make task automation possible. The script would contain the commands to do the tasks listed above, such as folder creation, file movement using loops, file deletion and so on. The benefit of shell scripts is that the code they contain can be re-used or adapted for similar tasks.
Practice 2b. Tidying up more carefully
In the process of doing the above, we actually made a few blunders. We accidentally deleted some files we should have kept either because they were missing a file extension. Because this automation is a complex operation that cannot be undone, we want to make sure we don’t make those kinds of mistakes again.
One way to do that is to check we have coded the workflow correctly before we finally execute the automation, possibly by simply printing to screen all the relevant filenames prior to moving them - that way, it is possible to check we are working on the right files before any action is taken.
To prevent accidental deletion of files, we could introduce a step to
check whether or not to delete a file, e.g., by using the remove command
rm in the Unix shell with an -i flag. The
-i flag forces the system to ask for confirmation on
whether or not to delete a file. One can answer either
Y or N to the example below.
 {alt=“RM command in the shell”,
width=“75%”}
{alt=“RM command in the shell”,
width=“75%”}
Practice 3. Managing incoming data
Suppose you have a number of acoustic listening devices set up in the forest. Every day, you receive an email from each device with an attached data file recording that day’s activity. In order to analyse the data from the devices, all the separate daily data files need to be combined weekly into a single file. It is important that each device ID is listed within a column in the combined data file to identify all the different locations.
In order to analyse the data over time, you need to append the weekly file digest to the existing, now very large, main data file. Before adding anything new, and in order to safeguard the integrity of the data, you need to create a backup of that main data file and send a copy of that backup file to your cloud storage account for safekeeping. Once the new data has been appended, you need to rename the new main data file with today’s date as part of the file name, and run software against the file to ensure the integrity of the data, e.g., to check that no data is missing (which might indicate a malfunctioning device).
Steps in the data combination process
- Create a new copy of the main data file with today’s date as part of the file name.
- Move the previous version of the main data file to cloud storage.
- Save all the new data files individually to local storage with the device ID of each as part of the file names.
- Create a new weekly data file digest into which the daily digests from the different devices will be imported.
- Import each daily digest to that data file with an
appendcommand, ensuring that the device ID relating to each file’s data is written into a separate column. - Append the weekly digest to the newly renamed main data file.
- Verify that no data is missing. In OpenRefine, using
Facet by Blankon the relevant data fields could be one way to verify that no data is missing.
Using a shell script to automate the work
Again, a shell script could be used to automate this work. Given that these tasks are run weekly, it would make sense to turn this into an automated task rather than a manual one as that will not only be faster, but will reduce the opportunity for error.